This blog shows how to design a relational database. You'll find lots
of other wordy articles on the Internet about third normal form, entity diagrams
and the like ... this one just uses common sense!
The Problem we're Trying to Solve
Imagine that you have decided to build a database of contacts for your
company or organisation (a common requirement). Here's what your current
Excel spreadsheet of contacts looks like:

The Excel spreadsheet containing your list of clients
You are getting more and more clients, and notice the following problems:
- Your company's data entry clerks keep mistyping company
names, making it difficult to extract meaningful data.
- Because you're storing duplicate company information more
than once, the size of your spreadsheet is becoming
unmanageable.
What you need is a relational database, consisting of different tables linked
together!
An Example of a Relational Database
Here's an example database diagram containing details of films (movies),
together with their directors, studios, etc:

All of the tables are joined together with relationships
The main table contains a list of films - for each film you can see (clockwise
from bottom left) its country of origin, language, director, studio and
certificate.
Access and SQL Server Terminology
All of this blog applies equally well to Access or SQL Server. The only
thing to note is that the two software applications use slightly different
terminology:
|
Access term |
SQL Server term |
What it means |
|
Field |
Column |
Any bit of information for a table |
|
Record |
Row |
Any collected set of fields |
These terms will make much more sense if you read the next heading.
I've chosen to include both terms in all cases.
Records/Rows and
Fields/Columns
Each table consists of a number of fields (or columns), each of which gives a
bit of information about each record (or row) in the table:

The
fields/columns for the films table are shown here - the field/column called
FilmName is shown selected. This holds the name of each film.
Here are some
of the records/rows in this table:

Each
record or row contains the details of one film (or movie, if you
prefer)
The Primary Key Field/Column
There is one very special field/column in each table: the primary key.
This is the field/column which uniquely defines each record/row:

The
primary key is shown with a key symbol next to
it. For the films table, it is the
FilmId field/column. Two films
may have the same name - for example:
Primary keys are nearly always autonumber or autoincrement numerical
fields/columns: that is, the first record/row is number 1, the second number 2,
etc.
One-to-Many Relationships
In a relational database, tables are linked together by relationships.
Far less exciting than the real-life equivalent, these show how a field/column
in one table is linked to its counterpart in another:

Here the
DirectorId field/column in the
tblDirector table shares a value with the
FilmDirectorId field/column in the
tblFilm table.
Every such relationship is one-to-many, or parent-child. What this means
is that for every pair of linked tables, one of the tables is a parent and one a
child. In our example above:
- the tblDirector table is the parent; and
- the tblFilm table is the child.
The reason for this is that every director can have lots of corresponding
films in the tblFilm table, but the converse is not true (we'll
ignore the case where a film has two or more different directors!).
How to Design a Database
The approach we'll take is to imagine each table is a peg, and decide which
bits of information we want to hang on which peg. So now that we've got
the theory behind us, let's look at how this works in practice!
Remember that we wanted to create a relational database from the following
raw data:

The first few clients (out of presumably many thousands)
Step One - Identifying the Pegs
If you look at the above example, some of the information is repeated.
For example, every time someone works for Shell we get repeated:
- Shell; and
- Oil and gas supplier
This is a bad idea for 3 reasons:
- It wastes space in the database (not a big issue if you only
have a few thousand records, but significant if you have a few
million).
- It wastes typing time (someone is going to have to type in
the repeated information).
- Above all it makes data errors significantly more likely (if
you have 100 people working for Shell, the chance of mistyping
the company name is high). As a consequence, any future
attempt to show all the people who work for Shell may omit some
data - which is really, really bad news.
To avoid repeated information as above, follow the main rule of database
design (as shown in the hint below).
If you find yourself typing in the same information twice, you should extract
it to another table.
For the above example, it is I hope by now reasonably obvious that there are two
"pegs" to
hang data on:
|
Peg |
What it contains |
|
Companies |
A list of all the companies |
|
People |
A list of all the people who work for these companies |
By storing the company name and description in a separate table, we'll avoid
having to type things in twice. Given this insight, we should now be able to assign the bits of information
in our spreadsheet to the two tables.
Some people call these pegs "entities", corresponding to physical things.
For example, in a movies database like IMDB entities would include the fllms
themselves, actors, directors, studios, certificates, genres, ratings and
languages, each of which would have a separate table.
Step Two - Identifying the Fields/Columns
We can assign the fields/columns shown in our spreadsheet to tables as
follows:
|
Field/Column |
Example |
Table |
|
First name |
Alan |
People |
|
Last name |
Arbib |
People |
|
Date of birth |
21-Feb-89 |
People |
|
Company |
Shell |
Companies |
|
Description |
Oil and gas supplier |
Companies |
Thus database design is simply a matter of good housekeeping: putting
fields/columns into the tables to which they belong. This gives us the
following two tables:

The two tables have no links between them as yet (you can't tell which people work for which companies).
However, the tables are not yet linked in any way - but before we can
consider this, we must first create primary keys for each table.
Step Three - Adding Primary Keys
For every table you create in a database, you should create a primary key:
a field/column whose value is different for each row/record.
For the tblPerson table, for example, you can't choose any
of the existing fields/columns - otherwise you will only be able to have one
person called Alan or Arbib or born on 21st
February 1989 in your table. The easiest solution is usually to create a
new field/column to number the records:

Our revised tables: each now has an additional field which numbers the rows or records.
Thus the PersonId field/column, for example, will hold a
different number for each person:

Here Fiona McBride is selected,
who has unique id number 3.
I think creating an id field/column to automatically number the records in a
table is always the best and simplest solution, even when another candidate
field/column exists. So if every product that your company sells has a
unique code, I'd still create a ProductId field/column and use
this as the primary key instead.
Step Four - Adding a Link Field
The only problem now is that we have two tables, with no way of linking them:
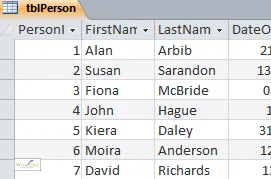
|
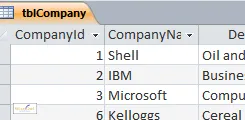
|
|
The table of people |
The table of companies |
To tie the two tables in together, we need to add one more field/column to
the tblPerson table, identifying for each person to which
company they belong:

The new
CompanyId field/column ties each person into a company.
Thus (for example) Alan Arbib works for company number 1, which
is Shell. The field called CompanyId in
the tblPerson table is sometimes called a foreign key.
Hence the beauty of relational databases: instead of storing all of Shell's
details against Alan Arbib, we're now just storing a 4-byte integer, and using
this to look up the other details. In the front-end menu of our
application, we can make sure that our user doesn't need to know the
CompanyId for each company by providing a drop-list instead.
Step Five - Creating the
Relationship
Potentially we can now tie each person to the company they work for. To
make this formal, we create a relationship:

The link between the two tables, as it appears in Access (SQL Server is similar).
Every relationship is one-to-many: in the example above, for each company we can
have potentially an infinite number of people working for it.
Referential Integrity and Cascade Deletion
The last buzzwords of this page, promise! For every relationship that
you create, you should normally enforce referential integrity and
cascade deletion. Here's what they mean:
|
Term |
What it means |
|
Referential integrity |
It's impossible to have orphans in the system (for our example, a person can't
have a CompanyId if no such corresponding row/record exists in
the table of companies). This is vital to preserve data integrity. |
|
Cascade deletion |
If you delete a parent, you should also delete all of the parent's children (for
our example, if you delete Shell from the companies table, you should also
delete all of the people who work for Shell; the obvious solution is not to
delete Shell in the first place!). |
That is almost all of the theory involved in relational databases.
However, there's one more thorny issue to discuss, which is how to cope with the
many-to-many relationships that exist everywhere in life.
In real life, people move jobs: so Bob may work for Shell one year, but IBM
the next. This inconsiderate behaviour on the part of human beings
complicates our database!

In the real world, you have two tables: the people who could potentially work for companies, and the companies for whom the people could work.
The link between the two tables shown above is therefore many-to-many:
- Each company can have many people working for it; but
- Each person can over the course of their lifetime work for
many companies.
Given that every relationship in a relational database is one-to-many, how
can we get round this?
The Answer: Creating a Child Table
The solution to this problem is to create a table which contains the children
of both the companies and the persons table. This will contain the
following fields/columns:
|
Field/column |
What it contains |
|
CompanyId |
The company for whom this person worked for this job |
|
PersonId |
The person who worked for this job |
|
DateJoined |
The date the person joined the company |
|
DateLeft |
The date the person left the company (may be blank) |
|
JobId |
The unique number of each record (see below) |
Thus the final database diagram would look like this:

The final design contains 3 linked tables
Choosing a Primary Key for Child Tables
You can create two different primary keys for tables like the jobs one above.
One possibility is to create a brand new field/column to number each record:

The
JobId field/column numbers each record
In the example above, the selected row/record shows that person number 1 (Alan
Arbib) started work for company number 3 (Microsoft)
on 1st May 2010, having previously worked at Shell
(company 1) and IBM (company 2).
The other possibility is to create a primary key based on the fact that the
combination of CompanyId and PersonId must be
unique:

Here the composite primary key contains the company and person numbers.
If you do go down this route, you must be certain that you can't repeat the same
PersonId/CompanyId combination in the table.
Thought: what happens if Alan Arbib decides at some point in the future to
rejoin Shell or IBM?
And that's it! A typical relational database will contain tens -
perhaps even hundreds - of tables joined together with relationships, but that's
essentially all of the building blocks taken care of.



